Borealid的答案包括测试并找出,这是难以赶超的建议。
并且测试这个可能比您想像的要多:您希望您的线程尽可能避开争用数据。假如数据完全是只读的,这么倘若您的线程正在访问“相似”数据,您可能会见到最佳性能——确保一次以小块的方式遍历数据,因而每位线程都从一遍又一遍的相同页面。假如数据是完全只读的深度linux,这么假如每位内核都有自己的缓存行副本就没有问题。(尽管这可能不会充分借助每位核心的缓存。)
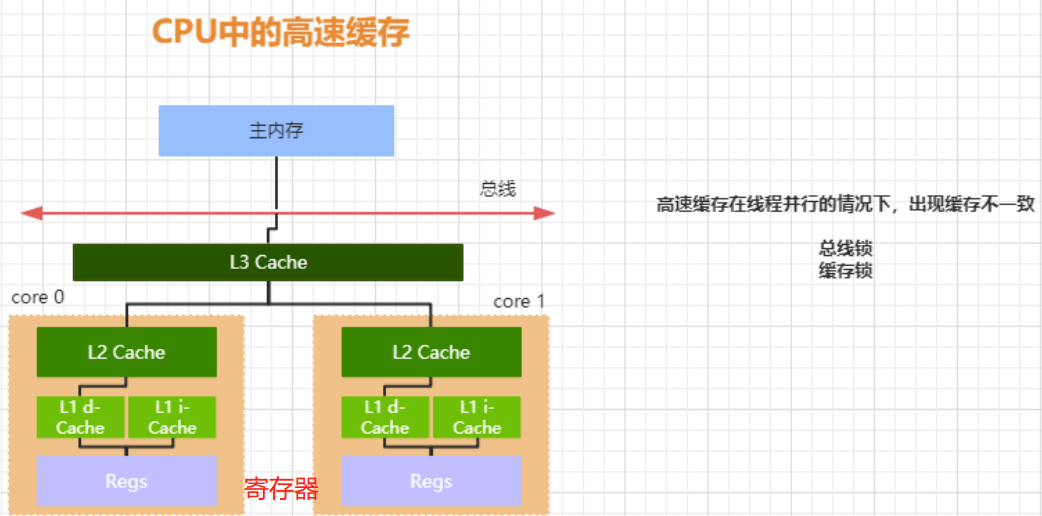
假如数据以任何方式被更改,这么倘若您通过一个好多。大多数缓存沿储存数据,而您急切希望保留每位缓存行在CPU之间大跌以获得良好的性能。在这些情况下,您可能希望让不同的线程在实际上相距很远的数据上运行,以防止互相碰撞。
所以:假如你在处理数据的同时更新数据,我建议使用N或2*N个执行线程(对于N个内核)linux内核源代码情景分析 扫描版,以SIZE/N*M作为起点,对于线程0到M.(0、1000、2000、3000,用于四个线程和4000个数据对象。)这将为您提供最好的机会,将不同的缓存行提供给每位核心,并准许在没有缓存行弹跳的情况下继续进行更新:假若您
+--------------+---------------+--------------+---------------+--- ...
| first thread | second thread | third thread | fourth thread | first ...
+--------------+---------------+--------------+---------------+--- ...
不在处理数据时更新数据,您可能希望启动N或2*N个执行线程(对于N个内核),以0、1、2、3等开始它们并联通每次迭代时linux内核源代码情景分析 扫描版linux认证,每位元素往前联通N或2*N个元素。这将容许缓存系统从显存中获取每位页面一次,用几乎相同的数据填充CPU缓存,并希望让每位核心都填充新鲜数据。

+-----------------------------------------------------+
| 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 ... |
+-----------------------------------------------------+
我还建议直接在您的代码中使用sched_setaffinity(2)以强制不同的线程使用它们自己的处理器。按照我的经验,Linux致力将每位线程保持在其原始处理器上,以至于不会迁移任务分配给其他闲置的核心。





